Vorlesung 1
In der Ersten Vorlesung haben wir uns zum Einstieg mit dem theme Netzwerkkommunikation und dann hauptsächlich mit dem Client-Server-Model beschäftigt.
Netzwerkkommunikation
Damit zwei Rechner miteinander kommunizieren, d.h. Daten austauschen können, muss eine Verbbindung hergestellt werden. Um dies zu ermöglichen, gibt es verschiedene Methoden, wie beispielsweise Netzwerkprotokolle, Ethernet-Verbindungen, WLAN und das Internet. Grundlegend dafür ist allerdings das Konzept von Netzwerken. Dies sind Zusammenschlüsse von Computern und anderen Geräten, welche lokal oder global sein können und durch physische Komponenten wie Netzwerkkabel, WLAN-router, Modems und Netzwerkschnittstellenkarten (NICs) verbunden sind. Der generelle Datenaustausch wird dann über verschiedene Protokolle und Standards geregelt, welche Regeln und Verfahren definieren, damit die reibungslose Datenübertragung sichergestellt werden kann. Mann sollte sich also Merken, dass für den Datenaustausch zwischen Rechnern Netzwerke, physische Komponenten und Protokolle nötig sind. Diese Seite wird allerdings nochmal genauer auf dieses Konzept eingehen und erklären, wie man solche Verbindungen herstellen kann.
Wie schon erwähnt, benötigt man eine physische Verbindung durch Netzwerkkabel, auch Ethernet Kabel genannt, welche das sogenannte Ethernet-Netzwerk bilden, um Daten zu übertragen. Daten werden hierbei in Datenpaketen, den Frames, verpackt und über das Netzwerk versendet. Wenn allerdings mehrere Rechner durch diese Kabel miteinander verbunden werden, kann es zu „Kollisionen“ der gesendeten Datenpakete kommen, welche sich dadurch neutralisieren würden und somit keine der Daten an ihrem gewünschten Ort ankommen würden. Um dies zu verhindern, gibt es Bridges und Switches, welche die Datenpakete innerhalb der Netzwerke managen und somit dafür sorgen, dass diese an ihrem Zielort, ohne Kollisionen, ankommen.
Bridging ist ein Prozess, bei dem eine Brücke zwischen zwei oder mehreren Netzwerken geschaffen wird, um die Kommunikation zwischen den Geräten in den verschiedenen Netzwerken zu ermöglichen. Dabei werden Datenpakete analysiert, gefiltert und entsprechend weitergeleitet. Switching hingegen bezieht sich auf die Weiterleitung von Datenpaketen innerhalb eines Netzwerks, insbesondere in einem lokalen Netzwerk (LAN). Ein Switch fungiert als Multiport-Gerät, das den Datenverkehr analysiert und anhand der MAC-Adressen der angeschlossenen Geräte die Weiterleitung der Pakete ermöglicht.
Das Kommunikationsmodel
Schauen wir uns die Kommunikation zwischen zwei Rechnern mal etwas genauer an!
Eine Netzwerkverbindung kann durch fünf Bestandteile Characterisiert werde. Man benötigt das Protokoll, die IP des lokalen Hosts, die Portnummer des lokalen Hosts, die IP des fremden Hosts und die Portnummer des fremden Hosts. IP-Adressen und Portnummer, dienen dazu die Kommunikationspartner zu identifizieren, da es mitlerweile viele Tausende Ports an einzelnen Geräten gibt und das verwendete Protokoll definiert das Format der Host-Adressen und die Identifikation der kommunizierten Prozesse. Die Daten werden dann in Pakete aufgeteilt und über das Netzwerk versendet und über verschiedene Netzwerkkomponenten geroutet, bis sie an ihrem gewünschten Ziel ankommen. Zusammengafasst bildet das Kommunikationsmodel die Grundlage für den Datenaustausch in zahlreichen Anwendungen und wer aufgepasst hat, wird diese Grundstrucktur im Server-Client-Model wiedererkennen.
Das Client-Server-Model
Das Client-Server-Modell erweitert das Kommunikationsmodell um die Begrifflichkeiten des Clients, also der Rechner, welcher eine Dienstleistung oder Ressource anfordert und der Server, welcher eine diese dann Bereitstellt bzw. eine Antwort liefert. Bei dem Client handelt es sich meistens um ein leistungsschwächeres Gerät, wie einen Benutzercomputer, ein Handy oder ein Tablet. Der Server hingegen ist normalerweise ein leistungssrarker Computer oder Softwareanwendung, welche bestimmte Resourcen, Dienste oder Informationen anbietet und so Cient-Anfragen berarbeiten kann. Die Kommunikation zwischen Client und Server erfolgt über ein Netzwerkprotokoll, wie zum Beispiel das TCP/IP-Protokoll. Der Client sendet eine Anfrage an den Server, der diese Anfrage verarbeitet und eine entsprechende Antwort generiert. Die Antwort wird dann an den Client zurückgesendet. Klingt vertraut oder? Beispiele für das Client-Server-Modell sind zahlreich, wie zum Beispiel das Abrufen von Webseiten über einen Webbrowser (Client) von einem Webserver (Server), das Versenden und Empfangen von E-Mails über einen E-Mail-Client (Client) und einen E-Mail-Server (Server) oder das Streamen von Videos von einem Video-Streaming-Server (Server) auf einen Streaming-Client (Client).
In diesem Kontext sollten wir uns nochmal diese Portnummern anschauen, für was bracuht man die nochmal? Portnummern spielen eine wichtige Rolle im Kommunikationsmodell zwischen Client und Server. Sie dienen nämlich dazu, den Austausch von Datenpaketen zwischen den beteiligten Computern zu organisieren und zu steuern. Sie sind numerische Kennungen, die einem bestimmten Dienst oder einer Anwendung zugeordnet sind und verhindern, dass es zu konflikten kommt, sollten mehrere Dienste oder Anwendungen gleichzeitig laufen. Im TCP/IP-Protokoll sind Portnummern 16-Bit-Zahlen, die von 0 bis 65535 reichen. Dabei sind die Nummern bis 1023 als sogenannte "Well-Known Ports" reserviert und bestimmten Standarddiensten zugeordnet. Beispielsweise ist Port 80 dem HTTP-Protokoll für Webseiten zugeordnet, während Port 25 für den E-Mail-Dienst SMTP verwendet wird.
Bei einer Kommunikation zwischen Client und Server wird die Portnummer sowohl auf der Client-Seite als auch auf der Server-Seite angegeben. Der Client sendet seine Anfrage an die IP-Adresse des Servers und gibt dabei die gewünschte Portnummer an. Der Server hört auf diesem spezifischen Port und empfängt die Anfrage des Clients. Dadurch können die Datenpakete gezielt an die richtige Anwendung weitergeleitet werden und mehrere Dienste und Anwendungen können konfliktfrei koexistieren!
- JavaScript und Frameworks (jQuery, u.a.)
- Java Applets
- native Apps in SWIFT bei IOS/Apple (früher objective-C)
- hybride und Web-Apps
Clientseitige Technologien:
- CGI (Common Gateway Interface)
- PHP
- Servlets
Serverseitige Technologien:
Serialisierung
Da sich dieses Kapitel mit den verscheidenden Zuständen befasst, welche Objekte annehmen können, ist es nötig ein grundlegendes Verständnis darüber zu besitzen, was Objekte überhaupt sind. Dafür finden sie eine Einführung in das Thema hier: „Objekte“ (LINK- Java Skript, V3), falls sie dies noch nicht gelesen haben. Um nun in das Thema einzusteigen, sollte festgehalten werden, dass wir uns für die kommenden Überlegungen im Rahmen einer objektorientierten Programmiersprache bewegen. Objekte haben ein Verhalten und einen Zustand. Ersteres bezieht sich auf die zugehörige Klasse und letzteres auf die einzelnen Objekte und wird meistens als Wert seiner Attribute repräsentiert. Wird ein Objekt nun einem Ereignis oder Methodenaufrufen ausgesetzt, kann sich dieser Zustand und sein zugehöriger Wert ändern. Diese Wertänderung kann und sollte man, mit Hilfe passender Methoden, speichern und wiederherstellen können, damit man beispielsweise bei einem Spiel nicht immer von Neuem beginnen muss, wenn man es geschlossen hat. Zur besseren Erklärung der Verwaltung von Objektzuständen, gehen wir nun von dem Beispiel eines Spiels aus, dieses besitzt die Klasse „Spielfigur“ mit den Objekten Stärke, Typ und Waffe. Wir haben also innerhalb des Spiels die Möglichkeit, verschiedene Figuren zu speichern welche unterschiedlichen Stärken, Typen und Waffen besitzen. Im verlauf des Spiels können diese Figuren stärker werden und andere Waffen erkämpfen, daher muss das Spiel in der Lage sein, verschiedene Zustände dieser Objekte zu speichern, damit man nicht immer von vorne beginnen muss sobald man das spiel schließt und wieder öffnet.
Wie speichern, bzw. serialisieren wir denn jetzt Objekte? Es gibt zwei verschiedene Ansätze für unser Ziel. Entweder fragen wir jedes Objekt ab und schreiben den Wert jeder Instazvariable in eine Datei, aber sind wir mal ehrlich, dafür wäre so ziemlich jeder zu faul, oder wir serialisieren unsere Objekte. Dies ist ein Objektorientierter Ansatz, bei welchem wir die Objekte auf ihre relevanten Daten "zusammendrücken",um sie ein einen speicherbaren oder übertragungsfähigen Zustand zu verwandeln. In anderen Worten werden die Werte der Instanzvariablen des Objekts ausgelesen und in eine spezielle Datenstruktur umgewandelt, die den Zustand des Objekts repräsentiert.
Um ein serialisiertes Objekt in eine Datei zu schreiben muss mann folgende schritte befolgen:
- Erzeugung eines FileOutputStreams
- Erzeugung eines ObjectOutputStreams
- Schreiben der Objekte
- Schließen des ObjektOutputStreams
FileOutputStream fileStream = new FileOutputStream („MeinSpiel.ser”);
ObjectOutputStream os = new ObjectOutputSream(fileStream);
os.writeObject(figur1);
os.writeObject(figur2);
os.close();
Diese Datenstruktur enthält die Werte der Variablen sowie Informationen über den Typ des Objekts, damit sie später wieder in ihren Ursprungszustand versetzt werden können, bzw. nicht ganz, aber damit beschäftigen wir uns bei der Deserialisierung. Während der Serialisierung werden auch andere Objekte, auf die das zu serialisierende Objekt verweist, ebenfalls serialisiert. Dadurch entsteht ein sogenannter Objektgraph, der alle miteinander verknüpften Objekte enthält. Ist ein Objekt des Graphen nicht serialisierbar, wird, solannge die referenzierte Instazvariable nicht übersprungen wird, zur Luafzeit eine Exception ausgelöst. Man Merke sich also: Bei der serialiserung wird entweder alles, bzw. alles zusammenhängende, gespeichert oder nichts.
Deserialisierung
Wir haben unsere Objjekte nun serialisiert und können sie nun speichern und transportieren. Aber wie bekomme ich sie wieder in einen ausführbaren Zustand?
Die Deserialiserung, was der Name schon etwas verrät, ist sozusagen der Umkehrungsprozess zur Serialsierung, bei welchem die serialisierten Daten eingelesen und in ihren ursprünglichen Objektzustand zurückgewandel werden. Dies passiert, wenn die Daten gelesen oder empfangen werden.
Die Deserialiserung erfolgt typischerweise so:
- Fileinput innerhalb ObjectInputStream
- Objekte lesen
- Objekte casten
- Objektinputstream schließen
Eine sehr wichtige Rolle spielt hierbei das Casten von Objekten von Objekten, da die Deserialisierung in der Regel generische Objekte, also vom Typ "Object", zurück. Durch das Casting von Objekten, konvertiert man diese in ihren Ursprünglichen Datentyp. Das bedeutet, dass das Objekt als eine spezifische Klasse behandelt wird, die von dem gecasteten Datentyp abgeleitet ist. Dadurch erhält man Zugriff auf die spezifischen Eigenschaften und Methoden dieses Datentyps, welche man ansonsten nicht effektiv nutzen könnte.
Das Casting von Objekten kann implizit oder explizit erfolgen. Implizites Casting tritt auf, wenn das Ziel des Castings ein übergeordneter Datentyp ist, von dem der ursprüngliche Datentyp abgeleitet ist. In diesem Fall ist kein expliziter Casting-Operator erforderlich.
Explizites Casting ist erforderlich, wenn das Ziel des Castings ein untergeordneter Datentyp ist oder wenn das Objekt zwischen nicht verwandten Klassen konvertiert werden soll. Hier wird der Casting-Operator verwendet, um das Objekt in den gewünschten Datentyp umzuwandeln. Es ist jedoch wichtig zu beachten, dass beim expliziten Casting ein Typüberprüfungsfehler auftreten kann, wenn das Objekt nicht wirklich mit dem Zieltyp kompatibel ist.
Ein String in eine Textdatei schreiben
Wir können nun Objekte serialisiern und deserialiseren. Aber wie können unsere geschriebenen Daten von anderen Programmen augelesen werden, welche beispielsweise ein "Nicht-Java-Programm" sind?
Für diesen Fall schreiben wir unsere Daten, also einen String, in eine einfache Textdatei und nutzen dafür den sogenannten Filewriter.
//Filewriter wird erstellt und Textdatei kreiert oder darauf zugegriffen
FileWriter writer = new FileWriter("test.txt");
//Mit der Funktion write() kann ein String in die Datei geschrieben werden
writer.write("Der Text der gespeichert werden soll")
Um anschließend auf die Dateien zugreifen zu können, wird die File Klasse benutzt. Diese erzeugt ein File Objekt, das z.B. eine Datei oder einen Pfad repräsentiert oder auch ein neues Verzeichnis anlegen kann. Verketten wir dies mit einem BufferedWritern müssen wir nicht jedes Element einzelnd schreiben, da dieser alle Daten sammelt und anschließend gemeinsam in die Datei schreibt. Diese tolle funktion von "Buffern", also gepufferten Klassen, haben wir ja bereits bei der serialiserung kennengelernt und auch beim Lesen von Dateien, kommen sie zum einsatz.
Hier verwenden wir die kombination aus FileReader und BufferedReader, wobei dabei alle Zeilen durch eine while Schleife eingelesen werden. Als Übung haben wir dafür eine Textdatei erstellt und mithilfe eines BufferedReaders und FileReaders eingelesen. Anschließend haben wir diese dann mit einem BufferedWriter und FileWriter ausgeben lassen, bzw. wurde der eingelesene Text in eine neue Datei geschrieben, wobei der text 1zu1 in der neunen Datei dargestellt wird. Zusammebfassend lässt sich sagen, dass das Schreiben von Strings in Textdateien die persistente Speicherung, den Datenaustausch und die Protokollierung von Informationen in einer zugänglichen und flexiblen Form. Es ist eine grundlegende Funktion, die in vielen Programmiersprachen vorhanden ist und in etwa den Datenfluss im kleinen Rahmen darstellt. Dernnächste schritt wäre dann nämlich der Datenfluss über Netzwerke, also zwischen Client und Server.
Vorlesung 2
Wir haben uns bereits das grundlegende Modell der Datenflüsse innerhalb von Netzwerken, also zwischen Client und Server, angeschaut. Da steckt natürlich noch eine Menge Arbeit dahinter, diese Verbindung überhaupt herzustellen und es gibt verschiedene Schritte und Technologien um dies zu erreichen. Der generelle Ablauf beginnt mit dem Starten des Servers, dann muss ein Client erstellt, eine Verbindung aufgebaut und hergestellt werden, anschließend findet die Datenübertragung statt und die Verbindung wird wieder abgebaut. Dabei ist es wichtig zu beachten, dass der genaue Verbindungsaufbau und die Kommunikation zwischen Client und Server von der verwendeten Technologie und den verwendeten Protokollen abhängen.
In der Vorlesung haben wir uns mit den sogenannten Sockets beschäftigt, andere Technologien sind beispielsweise das Hypertext Transfer Protocol (HTTP), Hypertext Transfer Protocol Secure (HTTPS), File Transfer Protocol (FTP) und viele mehr. Wobei TCP/IP Netzwerkprotokolle die grundlegende Kommunikation im Internet ermöglichen, also die Basis für viele andere Protokolle bilden.
TCP/IP-Sockets
Sockets sind Programmierschnittstellen (APIs), wobei ein Socket ein Objekt ist, welches eine Netzwerkverbindung zwischen zwei Maschienen repräsentiert. Und weil eine Netzwerkverbindung eine Beziehung zwischen zwei Maschienen ist, ist sie auch gleichzeitig eine Beziehung zwischen Sockets. Ein ServerSocket, welcher auf Client-Anfragen wartet und dessen neu erzeugten "new Socket()". Zusätzlich fungiert auch noch ein einfacher Socket für die Kommunikation zwischen Client und Server. Wichtig hierfür ist, dass die IP-Adresse und die TCP-Portnummer bekannt sind, also in einfachen Worten: "Wer ist der Server und auf welchem Port läuft er?".
//Erstellung eines Sockets mit der IP-Adresse und Portnummer
Socket sock = newSocket("192.168.3.113", 4000);
Hat man ein Socket erstellt, wird ein InputStreamReader, welcher mit einem BufferedReader verkettet ist, an den Datenstrom angebunden werden und welcher ungefähr so funktioniert wie der Reader in unserm Beispiel mit der Textdatei, nur dass die Verbindung nicht mit einer Datei, sondern mit einem Socket erfolgt.
InputStreamReader streamReader = new InputStreamReader(s.getInputStream());
BufferedReader reader = new BufferedReader(streamReader);
Um die Daten in das Socket des Client zu schreiben, verwendet man den PrintWriter. Dieser fungiert als Brücke zwischen den ankommenden Daten in Zeichenform und den Bytes, wlche er von den Sockets erhält und kann dann Strings, also für uns Lesbare Informationen, in die Socket-Verbindung schreiben. Hierführ müssen wir den Lowlevel-Verbindungsstrom des Sockets mit dem PrintWriter, durch Übergabe dessen Konstruktors, verketten und die Daten anschließend mit den Methoden "print()" oder "println()" ausgeben.
PrintWriter writer = new PrintWriter(sock.getOutputStream());
writer.println("Test Text");
Um dieses Konzept besser zu verstehen, haben wir einen Server und Client programmiert, welcher die "Tipps des Tages" ausgeben kann. Unser Client fordert also die "Tipps des Tages" vom Client an, welcher den (heutigen) "Tipp des Tages" zurücksendet. Die Tpps selbst sind hier als Stringauf dem Server gespeichert und werden in der Konsole des Clients ausgegeben.
Erstelung eines Chat-Clients
Ein Chat-Client ist eine Softwareanwendung, die es einem Benutzer ermöglicht, an einem Chat-Dienst teilzunehmen. Der Chat-Client wird auf dem Gerät des Benutzers (z. B. Computer, Smartphone, Tablet) installiert und stellt die Benutzeroberfläche bereit, über die der Benutzer mit anderen Teilnehmern des Chats kommunizieren kann. Einen simplen Chat-Client, welcher Nachrichten an einen Server senden kann, können wir relativ einfach schreiben. Wir müssten zunächst eine GUI, also ein Graphical User Interface, erstellen, in welches man text eingeben kann und über einen Senden-Button verfügt. Dann eine Netzwerkverbindung einrichten und mithilfe eines PrintWriters den Text aus dem Textfeld der GUI "holen" und an den Server senden.
Der Code wüde so aussehen:
Naja, aber Stopp...was bringt uns ein Chat-Client, welcher nur senden, aber keine Nachrichten empfangen kann?
Da dies Offensichtlich nicht zielführend währe, müssen wir einen Chat-Client schreiben, welcher beide Funktionen beherscht und wir mit dem Server und/ oder andern Chat-Clients kommunizieren können.
Dafür müssen wir uns jetzt allerdings erstmal das Konzept von Threads und Multithreading näher anschauen, da wir Nachrichten lesen wollen, sobald diese von Server gedendet werden, ohne extra eine Anfrage zu senden.
Threads
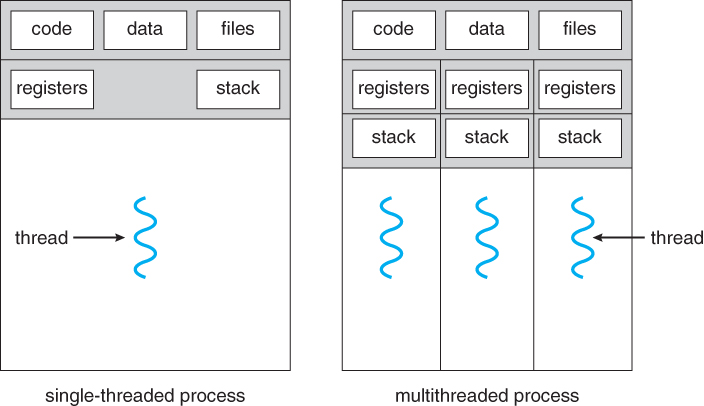
Ein Thread repräsentiert einen einzelnen Arbeitsablauf, beziehungsweise einen Ausführungsfaden oder "Handlungsstränge", innerhalb eines Prozesses.
Ein Prozess kann aus mehreren Threads bestehen, die parallel oder nacheinander ausgeführt werden können und wobei jeder Thread seinen eigenen Ausführungskontext hat und unabhängig von anderen arbeiten kann.
Die Parallele ausführung mehrere Threads, mit jeweils eigenen Stacks, wird als Multithreading bezeichnet und ermöglicht daher die gleichzeitige Ausführung mehrerer Aufgaben oder Prozesse in einem Programm, wass dessen Leistung und Reaktionsfähigkei verbessert.
Die Verwendung von Multithreading erfordert ein Multiprozessorsystem, da die Prozessoren Threads parallel ausführen können.
Ohne ein Multiprozessorsystem würde jeder Thread sequentiell laufen und nur den Anschein von Parallelität erwecken.
In Java wird Multithreading durch die Verwendung der Thread-Klasse aus dem Paket java.lang implementiert.
Um einen Thread zu starten, wird eine Instanz der Thread-Klasse erstellt.
Diese Instanz bietet Methoden zum Starten des Threads, zum Anhalten des Threads oder zum Herstellen einer Verbindung zu einem anderen Thread.
Der Hauptthread wird immer innerhalb der Hauptmethode gestartet.
Wenn zusätzliche Threads benötigt werden, können sie wie folgt erstellt und gestartet werden:
Thread thread1 = new Thread(new MeineRunnableKlasse());
thread1.start();
Thread thread2 = new Thread(new EineAndereRunnableKlasse());
thread2.start();
Durch die Erstellung und den Start dieser Thread-Instanzen können mehrere Threads parallel ausgeführt werden, um verschiedene Aufgaben gleichzeitig zu erledigen. Wenn ein Thread ohne zugewiesene Aufgaben programmiert wird, wird er direkt beendet. Um einen Thread eine spezifische Aufgabe ausführen zu lassen, kann ein Runnable-Objekt verwendet werden. Dieses Objekt implementiert das Runnable-Interface und enthält eine run()-Methode, die als Erstes im neuen Thread ausgeführt wird. Um einen Thread mit einer bestimmten Aufgabe zu starten, wird dem Thread-Konstruktor das entsprechende Runnable-Objekt übergeben. Dadurch wird der Thread mit der definierten Aufgabe gestartet.
ThreadScheduler
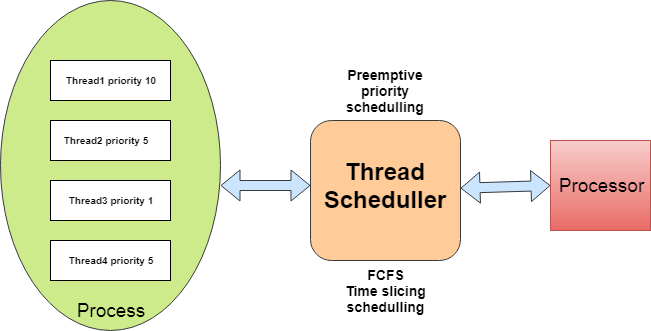
Ein wichtiger Aspekt hierbei ist die Synchronisation der Threads, um sicherzustellen, dass sie auf gemeinsame Ressourcen oder kritische Abschnitte des Codes in einer geordneten und konsistenten Weise zugreifen, was Wettlaufsituationen (Race Conditions) und andere Probleme verhindert. Dies wird durch den Thread-Scheduler erreicht. Dieser bestimmt die Ausführungszeit und Laufzeit eines Threads. Threads durchlaufen verschiedene Zustände, die als Thread-Lebenszyklen bezeichnet werden. Ein Thread befindet sich im Zustand "neu/erstellt", wenn er als Instanz erstellt, aber noch nicht gestartet wurde.
Nach dem Start wechselt ein Thread zwischen den Zuständen "ausführbar/lauffähig", "laufend" und "nicht ausführbar/blockiert". Wenn ein Thread bereit ist, aber noch nicht vom Scheduler geplant wurde, befindet er sich im Zustand "lauffähig". Ein Thread wird als beendet betrachtet, sobald sein Stack vollständig abgearbeitet ist. Die verteilung der der CPU-Zeit auf die Laufzeit eines Threads, bestimmen sie durch Priorisierung und bestimmung der Ausführungsreihenfolge der Threads. Die Laufzeit eines Threads kann von verschiedenen Faktoren beeinflusst werden, wie der Priorität des Threads, der Verfügbarkeit der CPU-Zeit und möglichen Blockierungs- oder Wartezeiten. Zusammenfassen ermöglicht diese Funktionsweise eine effiziente und gerechte Nutzung der Ressourcen.
Thread-Synchronisation und Gleichzeitigkeitsprobleme
Verlorene Aktualisierungen können auftreten, wenn mehrere Threads gleichzeitig auf die gleiche Ressource zugreifen und die Aktualisierungen nicht synchronisiert werden. Dadurch können Aktualisierungen verloren gehen und der endgültige Zustand der Ressource entspricht möglicherweise nicht den Erwartungen. Um den Verlust von Updates zu vermeiden, ist es wichtig, den Zugriff auf gemeinsam genutzte Ressourcen zu synchronisieren, da ansonsten Gleichzeitigkeitsprobleme aufteten können. Gleichzeitigkeitsprobleme treten auf, wenn mehrere Threads parallel auf gemeinsam genutzte Ressourcen zugreifen und dabei möglicherweise inkorrekte oder unerwartete Ergebnisse erzeugen. Diese Probleme entstehen, weil die Reihenfolge und der Zeitpunkt, zu dem Threads auf bestimmte Ressourcen zugreifen, nicht vorhersehbar sind.
Eine Möglichkeit, dies zu erreichen, besteht darin, das Schlüsselwort "synchronized" zu verwenden, das auf Methoden oder Codeblöcke angewendet werden kann. Durch die Synchronisierung von Methoden oder Blöcken wird sichergestellt, dass sie als atomare Einheit ausgeführt werden, sodass jeweils nur ein Thread gleichzeitig auf die Ressource zugreifen kann. Es ist jedoch zu beachten, dass die Verwendung synchronisierter Methoden die Leistung beeinträchtigen kann, da Threads gezwungen werden, aufeinander zu warten, was zu Verzögerungen führen kann. Durch eine gezielte Anwendung der Synchronisierung können gleichzeitig Zugriffe auf gemeinsam genutzte Ressourcen kontrolliert und konsistente Ergebnisse gewährleistet werden.
Im Kontext des SeverClients:
Ein Multithreading-Server-Client-Modell ermöglicht es, mehrere gleichzeitige Verbindungen zwischen einem Server und mehreren Clients zu verwalten.
Hierbei werden Threads eingesetzt, um die parallele Verarbeitung der Anfragen der Clients zu ermöglichen.
Der Server verwendet einen Hauptthread, der auf eingehende Verbindungen von Clients wartet.
Sobald eine Verbindung hergestellt wird, erstellt der Server einen neuen Thread, der sich um die Kommunikation mit diesem Client kümmert, während der Hauptthread weiterhin auf neue Verbindungen wartet.
So kann der Server mehrere Clients gleichzeitig bedienen und die Clients können Nachrichten senden und empfangen.
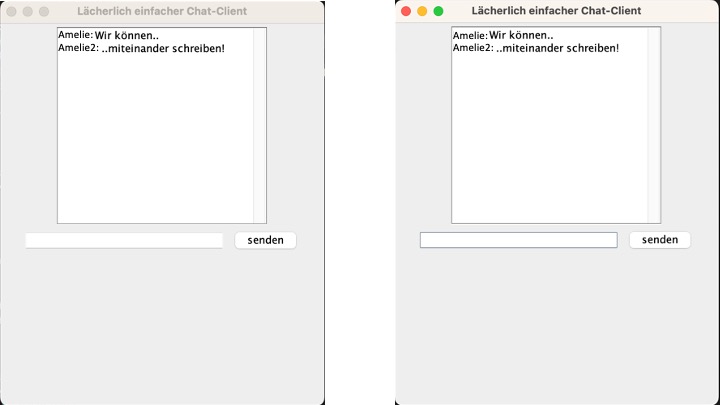
Im Laufe der Vorlesung haben wir einen Chat-Client gebaut, welcher Nachrichten Senden und Empfangen kann:
Vorlesung 3
Das Producer/Consumer-Problem
Das Producer/Consumer-Problem stellt eine Herausforderung dar, bei der Threads innerhalb eines Systems koordiniert werden müssen. Es tritt auf, wenn ein oder mehrere Producer-Threads Daten erzeugen und ein oder mehrere Consumer-Threads diese Daten konsumieren. Das Ziel besteht darin, sicherzustellen, dass die Producer- und Consumer-Threads so programmiert werden, dass Dateninkonsistenzen oder Deadlocks vermieden werden. Eine Lösung für das Producer/Consumer-Problem besteht in der Verwendung eines Puffers, der als Zwischenspeicher für die von den Producern erzeugten Daten fungiert, bis sie von den Consumern abgerufen werden. Man kann dies mit dem Konzept des Streaming vergleichen, bei dem Daten zunächst heruntergeladen und im Puffer zwischengespeichert werden, bis der Puffer voll ist. Dann können die Daten abgerufen und weiterverarbeitet werden.

Dieser Prozess lässt sich folgendermaßen beschreiben:
Sobald der Puffer dann eine bestimmte Kapazität erreicht oder nahezu voll ist, tritt der Consumer in Aktion und greift auf die Daten zu, um sie weiterzuverarbeiten.
Dabei wird der Puffer kontinuierlich geleert, indem die Daten daraus entnommen werden, um den Fluss der Verarbeitung aufrechtzuerhalten.
und es ist von großer Bedeutung, dass kontinuierlich neue Daten in den Puffer geladen und auch wieder daraus entladen werden, um einen reibungslosen Datenfluss sicherzustellen.
Das Versagen eines dieser beiden Vorgänge kann schwerwiegende Konsequenzen haben. Einerseits kann es zu einer Überfüllung des Buffers führen, wodurch Daten verloren gehen können. Andererseits kann es zu Verzögerungen bei der Datenübertragung kommen, was zu langen Ladezeiten führt.
Die Koordination des Zugriffs auf den Puffer stellt eine Herausforderung dar, um Situationen zu vermeiden, in denen mehrere Threads gleichzeitig auf den Puffer zugreifen und Inkonsistenzen verursachen können, verwenden wir zwei Methoden der Klasse "Object": "wait()" und "notify()". Die "wait()" Methode bewirkt, dass der aktuell ausgeführte Thread anhält und auf die Ausführung einer "notify()" oder "notifyAll()" Methode für das entsprechende Objekt wartet.
Insbesondere ist die "notify()" Methode wichtig, da sie einen einzelnen Thread reaktiviert, der im Wartezustand bezüglich des Objekts ist.
Durch die korrekte Anwendung dieser Methoden kann der Zugriff auf den Puffer koordiniert werden, um Inkonsistenzen zu vermeiden und einen geordneten Datenfluss sicherzustellen.
Im Verlauf der Vorlesung wurde mir erst richtig bewusst, wie herausfordernd es sein kann, Daten zwischen verschiedenen Programmen zu übertragen und wie viel Komplexität eine scheinbar einfache Aufgabe mit sich bringen kann.
Vorlesung 4 und 5
Kommunikation zwischen Client und Webservern
Die Kommunikation zwischen Clients und Webservern ist ein wesentlicher Bestandteil des Internets. Clients sind in der Regel Webbrowser, während Webserver die Websites und deren Inhalte bereitstellen. Die Kommunikation erfolgt über das HTTP-Protokoll (Hypertext Transfer Protocol), das als Standardprotokoll für den Austausch von Daten zwischen einem Client und einem Webserver dient. Der Prozess beginnt damit, dass der Client eine Anfrage an den Webserver sendet. Diese Anfrage kann verschiedene Informationen enthalten, wie beispielsweise die gewünschte Webseite, zusätzliche Parameter oder Cookies. Der Webserver empfängt die Anfrage und verarbeitet sie entsprechend. Dabei kann der Server auf Datenbanken oder andere Ressourcen zugreifen, um die angeforderten Informationen zu generieren. Sobald der Webserver die Anfrage bearbeitet hat, sendet er eine Antwort zurück an den Client. Diese Antwort enthält normalerweise den angeforderten Inhalt, wie HTML, Bilder, CSS oder JavaScript. Die Antwort kann auch zusätzliche Informationen enthalten, wie z.B. den HTTP-Statuscode, der den Erfolg oder Misserfolg der Anfrage angibt. Insbesondere werden die beiden Methoden "get" und "post" verwendet.
Der Hauptzweck der "get"-Methode besteht darin, Informationen vom Server abzurufen. Der Client sendet also eine Anfrage an den Server und gibt dabei bestimmte Parameter in der URL an, welche normalerweise in der Adesszeile des Browsers sichtbar werden. Sie eignet sich gut nfragen, bei denen keine sensiblen Daten übertragen werden und bei denen es eher um das Abrufen von Informationen geht, z. B. das Anzeigen einer Webseite oder das Suchen nach Inhalten.
Bei der "post"-Methode besteht nicht nur die Möglichkeit, Daten anzufordern, sondern auch gleichzeitig Daten, wie beispielsweise Formulareingaben, an den Server zu senden. Und im Gegensatz zur GET-Methode werden die Daten nicht in der URL übertragen, sondern im Body der Anfrage. Dies macht die POST-Methode geeignet für das Senden von sensiblen oder größeren Datenmengen, z. B. wenn ein Formular ausgefüllt und an den Server gesendet wird. Die übermittelten Daten sind nicht direkt in der URL sichtbar, was die Sicherheit erhöht.
Man sollte sich den Unterschied zwischen den beiden Methoden also gut einprägen, um die entsprechende Methode für den jeweiligen Zweck korrekt auszuwählen und so eine effektive und sichere Kommunikation zu gewährleisten.
Servlets
Um noch einen schritt weiter zu gehen, schauen wir uns jetzt Servlets an. Servlets sind Java-Klassen, die in der Webentwicklung eingesetzt werden, um die Verarbeitung von HTTP-Anfragen auf dem Server zu ermöglichen. Sie dienen als Zwischenschicht zwischen dem Client, welcher meist ein Webbrowser ist und dem Webserver. Generell verarbeiten sie HTTP-Anfragen, generieren dynamische Inhalte wie beispielsweise HTML-Seiten, dienen der Datenverarvbeitund- und validierung, der Sitzungsverwaltung und Fehlerbehebung. Man könnte also sagen, sie sind ziemliche allrounder. Entwicklt werden sie in in Java und bereitgestellt und ausgeführt anschließend in Webcontainern wie z.B. unser Beispiel in Apache Tomcat.
Wie wir solche Servlets entwickeln, werden wir gleich sehen, allerdings ist an dieser Stelle anzunerken, dass auch neuere Technologien in der Webentwicklung gibt, wie z.B. JavaServer Faces, JavaServer Pages und Spring MVC. Trotzdem sind Servelts noch weit verbreitet, werden stehts weiterentwickelt und bieten eine solide Basis für die Erstellung leistungsfähiger, skalierbarer und sicherer Webanwendungen.
Um ein Servlet zu programmieren, muss zunächst ein Java-Projekt anlegen, eine Java-Klasse erstellen, welche das Servlet repräsentiert und das javax.servlet.Servelt - Interface implementiert und dies anschließend Konfigurieren. Dies wird normalerweie in einer "web.xml" Datei erreicht, indem dieser eine Konfiguration und eine URL-Mapping-Information hinzugefügt wird, welche später im Browser aufgerufen werden kann.
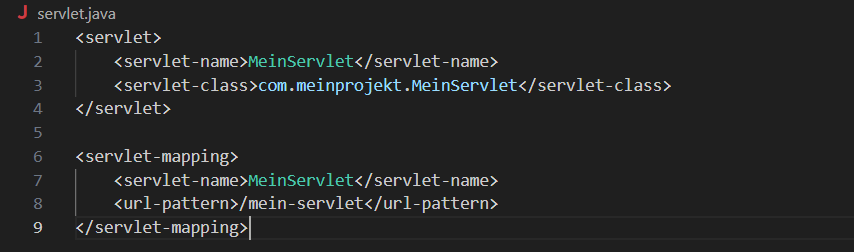
Dies kann auch mithilfe einer Annotation wie beispielsweise @WebServlet, erreicht werden. Die Servlet-Logik wird in der Java Datei abgelegt und umfasst Methoden wie "doGet()", "doPost()", "doPut()", basierend auf den Anforderungen, welche die Anwendung erfüllen soll. Um Das Projekt in einem Webcontainer lauffähig zu machen, muss es zunächst kompiliert und anschließend in einer WAR-Datei verpackt werden. Diesen Webcontainer kann man anschließend über Webcontainer wie Apache Tomcat hosten und im Browser anzeigen lassen. Apache Tomcat läuft typischer Weise auf "localhost:8080", dies kann man aber auch individuell konfigurieren, sollte der Port beispielsweise von der Firma besetzt sein. Um Tomcat zu starten, kann man entweder manuel in die Bin-Folder gehen und die Anwendung starten oder durch den aufruf via des Terminals. Hierzu muss man in das Bin verzeichnis zugreifen und die Datei "startup.bat" (Windows) bzw. "startup.sh" (Unix/Linux/Mac) aufrufen. Das Hosten geht hier eigentlich recht einfach, mann muss seine kompilierte Datei in der "Webapp"-Folder des Tomcatverzeichnisses ablegen, Tomcat starten und im URL den gewünschten Pfad angeben. Dazu schreibt man einfach den Namen des Projekts und den Namen des Servlets, getrennt durch Slash, hinter die localhost-Adresse. Möchte man die Anwendung beenden, macht man dies wie beim start, jedoch mit den Aufrufen "shutdown.bat" (Windows) bzw. "shutdown.sh" (Unix/Linux/Mac).
JavaServer Pages
Wir haben uns jetzt schonmal eine der in Vorlesung 1 genannten serverseitigen Technologien, die Servlets angeschaut, nun machen wir einen kleinen Exkurs zu den "JavaServer Pages", kurz JSP. Diese sind auch eine Technologie für die Erstellung von Webseiten, jedoch spezifisch für dynamische, da sie eine Kombination aus statischem HTML oder XML mit Java-Code zu verbinden und so interaktive und datenbankgesteuerte Webanwendungen zu erstellen. Gennerell sind JSPs einfach eine Erweiterung von Servlets, die Java-Code direkt in die HTML-Seite einbetten und sich die Enwickler dadurch besser auf das Design der Benutzeroberfeläche konzentrieren können, ohne den Java-Code seperat schreiben zu müssen. Hierbei wird der JavaCode einfach in spezielle Tags eingebettet, worin Java-Code, Ausdruckswerte und Variablen und Methoden eingefügt werden.
Sie können aber auch als "Zwischenstopp" zwischen einem Servlet und einem Server fungieren. In einer solchen Konfiguration übernimmt das Servlet die Verarbeitung der Anfragen und kann dann die Daten an eine JSP-Datei übergeben, die für die Darstellung der Benutzeroberfläche zuständig ist. Die JSP kann dann den generierten HTML-Code an den Client senden. Dies Trennt also zwei Prozesse voneinander, was den Code sauberer und die zusammenhängenden Prozesse laufen geordneter ab.
MVC
MVC steht für "Model-Viewer-Controller" und ist ein Entwurfsmuster, welches insbesondere bei der Entwicklung von webbasierten Anwendungen verwendet wird. Das Ziel von MVC ist es, die Trennung von Datenmodellen (Model), Benutzeroberfläche (View) und Anwendungslogik (Controller) zu ermöglichen, um die Wartbarkeit und Erweiterbarkeit des Codes zu verbessern.
Dabei repräsentiert das Model die Daten und Geschäftslogik der Anwendung, die View steht für die Darstellung der Benutzeroberfläche und der Controller für die Koordination dazwischen. Generell gesehen werden also Klassen, Daten Interaktionen (Model) von HTML, CSS, JavaScript Code (View) und den Benutzerinteraktionen (Controller) getrennt. Der Controler interpretiert hierfür die Benutzereingaben und führt die entsprechenden Aktionen im Model aus, um die Daten zu aktualisieren, und aktualisiert dann die View, um die Änderungen anzuzeigen.
Vorlesung 6
APPs
Apps sind Softwareanwendungen, welche auf mobilen Geräten wie Smartphones, Tablets oder anderen tragbaren geräten ausgeführt werden, aber dies ist ihnen ziemlich wahrscheinlich schon bekannt.
Es gibt drei Hauptarten.
- Die native Apps, welche nur auf bestimmten Plattformen wie IOS oder Google laufen, da sie speziell dafür entwickelt und auch nur im jeweiligen AppStore runtergeladen werden können.
- Die Alternative sind Web-Apps, welche über einen Webbrowser auf mobilen Geräten ausgeführt und über das Internet bereitgestellt werden. Das heißt, der Benutzer muss sie nicht extra runterladen und hat eine ähnliche Benutzererfahrung wie bei einer native App.
- Die letzte Art, die Progressive Web Apps, zielen darauf aus, die Lücke zwischen native und web Apps zu schließen und sind eine Art von Web-Apps, die fortschrittliche Funktionen und Eigenschaften bieten, die normalerweise mit nativen mobilen Apps assoziiert werden. Sie verfügen beispielsweise über responsives Design, Push-Benachrichtigungen, Offline-Fähigkeit und die Möglichkeit, die App auf den Startbildschirm des Geräts zu instalieren. Diese Funktionsweise wird dadurch erreicht, dass im Hintergrund Java-Script-Code ausgeführt und jede PWAs verfügen über einen eigenen Cache, welcher über eingehende Anfragen entscheiden und diese anschließend beantworten kann, ohne eine aktive Internetverbindung zu benötigen.
Innerhalb von PWAs und Apps im generellen unterscheidet man nochmal zwischen Single Page Application (SPA) und Multi Page Application (MPA). Ersteres verfügt nur über eine einzige HTML Seite und ihr Content wird direkt über JavaScript gerändert. Letzteres verfügt über mehrere HTML Seiten und ihr Content wird von Server gerendert.
Der MERN-Stack
Der Mern-Stack steht für MongoDB, Express.js, React und Node.js und ist ein sogenannter Stack oder eine Kombination von Technologien, die zusammen verwendet werden, um Full-Stack-Webanwendungen zu entwickeln.
MongoDB
MongoDB ist eine NoSQL-Datenbank, die in MERN als Datenbankkomponente verwendet wird. Sie ermöglicht das Speichern und Abrufen von Daten in einem flexiblen, dokumentenorientierten Format und verwendet dabei JSON-ähnliche Dokumente.
Express.js
Express.js ist ein Webframework für Node.js, das als Backend-Komponente in MERN verwendet wird. Es erleichtert das Erstellen von APIs (Application Programming Interface) und das Verarbeiten von HTTP-Anfragen und -Antworten, bietet dabei zugleich eine einfache und flexible Möglichkeit, Serverseitenlogik zu implementieren und Routen zu definieren.
React
React ist eine JavaScript-Bibliothek zur Entwicklung von Benutzeroberflächen. Sie wurde von Facebook entwickelt und wird heute von einer großen Entwicklergemeinschaft unterstützt. Sie verfügt über fertig designte Komponenten, eun Virtuelles DOM, JSX-Synatx und eine einwegige Datenflussrichtung, welche Entwicklern ermöglicht, interaktive und reaktive Benutzeroberflächen für Webanwendungen zu erstellen.
Node.js
Node.js ist eine Laufzeitumgebung, die es ermöglicht, JavaScript außerhalb des Webbrowsers auszuführen. Im MERN-Stack wird Node.js als Backend-Plattform verwendet. Es bietet die Möglichkeit, JavaScript auf dem Server auszuführen und bietet eine Vielzahl von Funktionen und Modulen, die zur Entwicklung von serverseitiger Logik und zur Kommunikation mit der Datenbank verwendet werden können.
Asynchrone Programmierung
Asynchrone Programmierung bezieht sich auf die Entwicklung von Code, der Aufgaben oder Operationen ausführt, ohne den Fluss des Hauptprogramms zu blockieren. In asynchroner Programmierung können mehrere Aufgaben gleichzeitig ausgeführt werden, wodurch die Effizienz und Reaktionsfähigkeit von Anwendungen verbessert wird.
Promises sind ein Konzept in der JavaScript-Programmierung, das bei der asynchronen Verarbeitung von Code hilfreich ist. Sie stellen eine Möglichkeit dar, asynchrone Operationen zu verwalten und das Ergebnis (entweder den Erfolg oder den Fehler) einer asynchronen Aufgabe zu behandeln.
Im Wesentlichen ermöglichen Promises die Verkettung von asynchronen Operationen in einer les- und wartbaren Weise. Anstelle von tief verschachtelten Callback-Funktionen (Callback Hell) bietet das Promise-Konzept eine klarere und strukturierte Art und Weise, asynchronen Code zu schreiben.
Ein Promise repräsentiert den zukünftigen Erfolg oder Fehler einer asynchronen Operation.
Es hat drei Zustände:
| Pending: | Der initiale Zustand des Promises, während die asynchrone Operation ausgeführt wird. |
|---|---|
| Fulfilled: | Der Zustand, in dem die asynchrone Operation erfolgreich abgeschlossen wurde und ein Ergebniswert verfügbar ist. |
| Rejected: | Der Zustand, in dem die asynchrone Operation fehlerhaft abgeschlossen wurde und ein Fehlerwert vorliegt. |
Ein Promise-Objekt hat die Methode .then(), die verwendet wird, um eine Funktion zu registrieren, die ausgeführt wird, wenn das Promise erfolgreich erfüllt wird, und die Methode .catch(), um eine Funktion zu registrieren, die ausgeführt wird, wenn das Promise abgelehnt wird. Dadurch wird eine kontrollierte Behandlung von Erfolgen und Fehlern ermöglicht.
Darüber hinaus ermöglicht die Verwendung von Promises die Verkettung von asynchronen Operationen mit der Methode .then(). Dadurch können mehrere asynchrone Operationen nacheinander ausgeführt werden, wobei jedes Promise in der Verkettung auf das Ergebnis des vorherigen Promises zugreifen kann.
Die Einführung von Promises in JavaScript hat die Entwicklung von asynchronem Code erleichtert und verbessert die Lesbarkeit, Wartbarkeit und Fehlerbehandlung. Promises sind mittlerweile in JavaScript zum Standard geworden und werden in vielen modernen Frameworks und Bibliotheken verwendet.
Einzelthema
Als vertiefungsthema habe ich mir in diesem Semester das Thema "Sicherheit von Webanwendungen" ausgesucht. Ich fand es sehr interessant, zu lernen wie man Webanwendungen generell konzipiert und schreibt, habe mich dabei aber immer gefragt, wie große Anbieter diese schützen. In einem der Vorherigen Kapitel hatten wir ja verschiedene Protokolle kennengelernt. Dabei war auch das HTTPS Protokoll, welches eine Erweiterung des HTTP um den faktor "Secure" ist und ich hatte mich dann gefragt, was da genau der Unterschied ist. Zum Einstieg werde ich auf verschiedene Aspekte der Sicherheit von Webanwendungen eingehen, mit Beispielen erklären und anschließend nocheinmal auf den Unterschied von HTTP und HTTPS eingehen, bzw. zuordnen welcher Aspekt hier angewendet wird.
Warum müssen wir Webanwendungen überhaupt schützen und vor was?
Webanwendungen müssen vor einer Vielzahl von Angriffen geschütz werden, wobei die Motivation dahinter sehr unterschiedlich sein können. Von Datendiebstahl, Finanziellem Interesse und Rufschädigung, bis hin zu Sabotage, Zugriff und Diebstah von Vertraulichen Daten oder acuh Ideologischer oder politischer Motivation, können diese Angriffe sein, natürlich auch abhängig von der Anwendung.
Bei uns im Unternehmen gibt es daher beispielsweise Trainings, Maßnahmen und Richtlinien, welche eingehalten werden müssen um die Sicherheit der Daten zu gewährleisten. Natürlich können wir als Nutzer nicht immer alle Gefahren richtig einschätzen, wenn wir uns in Web bewegen, daher ist es wichtig Webanwendungen bereits sicher zu gestalten oder eine Funktion zu haben, die dies für einen erkennt.
Wenn ich meinen Arbeitsrechner benutze werden daher beispielsweise Seiten blockiert, welche das Sicherheitssystem meiner Firma als kritisch einstuft, ich aber eventuell übersehen hätte oder blockiert die Instalation gewisser Dienste. Manchmal kann das etwas nerven, aber dies ist nur eine von vielen Aspekten, wie man Anwendungen und auch Nutzer vor Angriffen im Netz schützt.
Wichtigste Bedrohungen:
| Injection-Angriffe |
Hierbei handelt es sich um die einschleusung von bösartigen Daten, wie beispielsweise SQL-XML- oder OS-Befehlen, in Eingabefelder oder Parameter um die Integrität und Sicherheit der Anwendung zu kompromittieren.
|
|---|---|
| Cross-Site Scripting (XSS) |
Diese Angriffe zielen darauf ab, bösartigen Code in Webseiten einzufügen und Nutzer dazu zu bringen, diesen Code auszuführen. Dadurch können Angreifer sensible Informationen stehlen oder Benutzersitzungen kapern. |
| Cross-Site Request Forgery (CSRF) |
Bei dieser Art versucht ein Angreifer, eine Aktion im Namen des Opfers auszuführen, indem er eine gefälschte Anfrage sendet. Dies kann dazu führen, dass Nutzer ungewollt Aktionen ausführen, ohne es zu bemerken. |
| Unsichere Direktiven |
Unsichere Konfigurationen und Standardwerte können es Angreifern ermöglichen, auf sensible Dateien oder Ressourcen zuzugreifen oder Schwachstellen in der Anwendung auszunutzen.
|
| Brute-Force-Angriffen |
Bei Brute-Force-Angriffen versuchen Angreifer, Passwörter oder Schlüssel durch Ausprobieren aller möglichen Kombinationen zu erraten. Dies kann zur Kompromittierung von Benutzerkonten führen.
|
| Session-Hijacking |
Hierbei versucht ein Angreifer, die Sitzung eines authentifizierten Benutzers zu übernehmen, um auf geschützte Ressourcen zuzugreifen oder Aktionen im Namen des Benutzers auszuführen.
|
| Denial-of-Service (DoS)-Angriffe |
Diese Angriffe zielen darauf ab, die Verfügbarkeit einer Webanwendung zu beeinträchtigen, indem sie den Server mit einer großen Anzahl von Anfragen überlasten oder Schwachstellen in der Anwendung ausnutzen.
|
| Malware-Infektionen |
Durch den Upload von bösartigen Dateien oder den Besuch infizierter Websites können Webanwendungen mit Malware infiziert werden, was zu Datenverlust, Informationsdiebstahl oder anderen Schäden führen kann.
|
Dies sind nur einige der vielen Wege, wie es andere Parteien versuchen, sich zugriff auf Webanwendungen zu verschaffen und wir haben nur die Technischen angeschaut und die beeinflussung von Menschen herausgelassen, die dazu gebracht werden vertrauliche Informationen preiszugeben. Zudem entwickeln sich die Anzahl und Technik dieser Bedrohungen auch immer weiter, daher ist es wichtig, dass Webanwendungen kontinuierlich überwacht, aktualisiert und mit Sicherheitsmechanismen wie Zugriffskontrollen, Datenvalidierung und Verschlüsselung.
Sicherheitssmechanismen für Webanwendungen
Wir haben jetz schonmal kennengelernt, welche Arten von Bedrohungen es gibt und welche Motivation hinter solchen Angriffen stecken, nun muss man sich die Frage stellen, wie man diese Verhindert. Auch hier gibt es eine vielzahl von Mechanismen und Methoden, welche sich entsprechend weiterentwickeln und es kommen immer wieder mehr technologien auf den Markt, um der Schnellebigkeit der Bedrohungsentwicklung entgegenzuwirken. Alle können wir daher nicht behandeln, also befassen wir uns mit den am häufigsten angewendeten und daher wichtigsten Sicherheitsvorkehrungen.
Die Basis-Anforderungen werden vom Bundesamt für Sicherheit in der Informationstechnik, kurz BSI, für die Entwicklung von Webanwendungen Vorgeschireben und müssen von Entwicklern eingehalten werden. Dazu zählen eine sichere und angemessene Authentisierung, Zugriffskontrolle durch eine Autorisierungskomponente, ein sicheres Session-Management durch die zufällige Erstellung der Session-ID´s, mit ausreichender Entropie, Kontrolliertes Einbinden von Inhalten bei Webanwendungen, nicht beeinflussbare Upload-Funktion, Schutz vor unerlaubten, automatischen Zugriffen, Datenschutz durch die ausschließliche Verwendung der HTTP-POST-Methode zur Übertragung von Daten, Eingabevalidierung und Ausgabekodierung, Einsatz von "Stored Procedures" zum Schutz vor SQL-Injections und die Restriktive Herausgabe sicherheitsrelevanter Informationen, es sollen also keine Informationen preisgegeben werden, welche Informationen über Sicherheitsmechanismen herausgeben. Wie gesagt, dass ist ganz schön viel, obwohl dies nur die Basis-Anforderungen waren, Standart-Anforderungen wie beispielsweise Mehr-Faktor-Authentisierung, sind hier garnicht aufgelistet, da diese zwar empfehlenswert aber nicht vorgeschrieben sind. Alles in allem also ein sehr komplexes, aber auch spennendes Thema!
Im Folgenden schauen wir uns drei dieser Anforderungen und zugehörigen Schutzmechanismen inklusive Beispiel-Code an. Dazu habe ich mich auf Authentifizierung durch JSON WebTokens, Schutz vor SQL-Injections durch Prepared Statements und Datenverschlüsselung durch SSL/TLS beschränkt.
Authentifizierung durch JSON WebTokens
Jason Web Tokens, kurz JWTsm sind eine Methode zur sicheren Informationsübertragung zwischen zwei Parteien, in Form von JSON-Objekten. Die JWTs selbst, bestehen aus drei Komponenten: Dem Header, dem Payload und der Signatur, wobei jeder Teil Base64-Kodiert und durch Punkte getrennt ist. Die Base64-Kodierung ist die Darstellung von binären Daten als ASCII-Zeichenfolge, sie ist aber KEINE Verschlüsselung, sondern lediglich eine Methode zur Umwandlung von Daten in eine lesbare Zeichenfolge. Die JWTs werden in der Regel in den Autorisierungs-Header von HTTP-Anfragen geschrieben, wo sie von den Servern exthrahiert und interpretiert werden. Sie sind also eine Client-Server-Technologie und sind dabei grundlegend zustandslos, d.h. dass der Server keine Informationen über den Token oder den Zustand des Benutzers speichern muss. Der Server kann den Token verifizieren und die darin enthaltenen Informationen verwenden, um Berechtigungen zu überprüfen und bestimmte Aktionen zuzulassen oder abzulehnen.
In den Header werden Informationen über den verwendeten Algorithmus, wie beispielsweise HMAC, RSA oder ECDSA zur Signaturprüfung geschrieben. Der Payload enthält dann die eigentlichen Daten, welche Übertragen werden sollen. Dies sind sogenannte CLaims, welche Informationen über den Benutzer oder zusätzliche Metadaten beinhalten und in drei Kategorien unterteilt werden können. Die registierten, öffentlichen und privaten Claims.
Im Folgenden, sehen sie einen vereinfachten Beispielcode für ein JWTs. Header und Payload sind JASON-Objekte und Base64-Codiert und die Signatur wird mithilfe des geheimen Schlüssels und des HMAC-SHA256-Algorithmus erstellt.
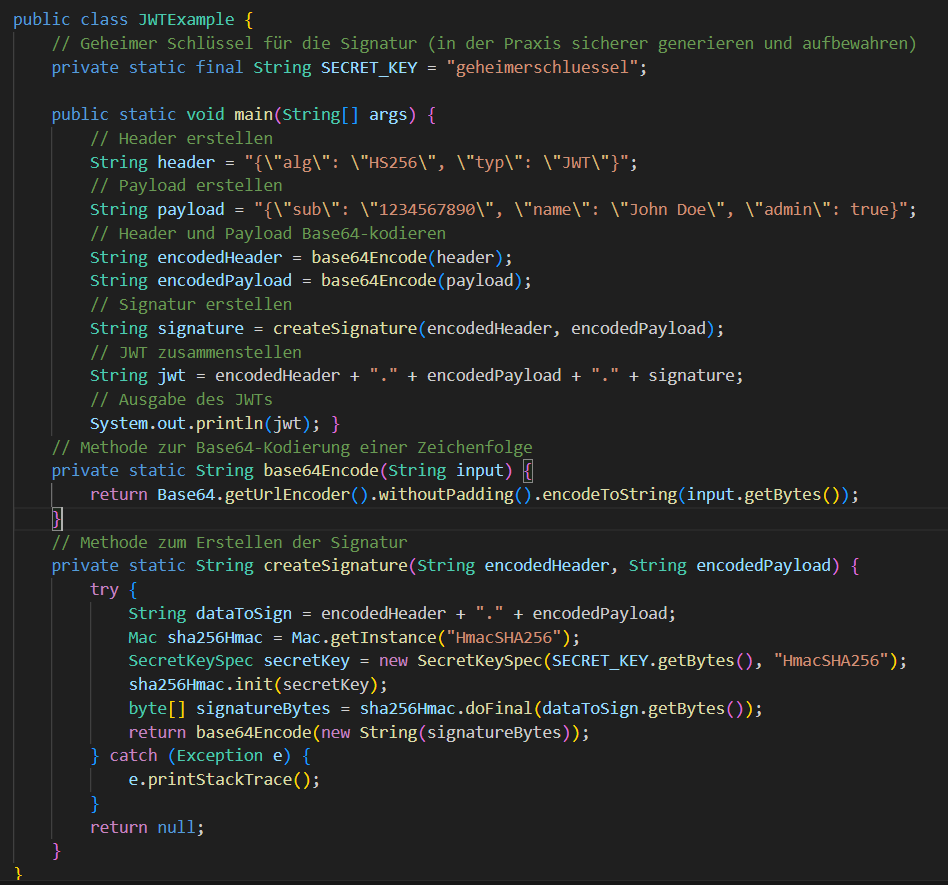
Die Verwendung von JWTs in der Praxis umfasst viele weitere Sicherheitsaspekte, wie die Wahl eines sicheren Algorithmus, die Verwaltung des geheimen Schlüssels, die Überprüfung der Signatur, die Token-Verfallszeiten usw. Dieses Beispiel dient lediglich zur Veranschaulichung der Grundprinzipien eines JWTs.
Prepared Statements
Prepared Statements sind vorgeschriebene SQL-Anweisungen, welche Parameter als Platzhalter verwenden und später mit den tatsächlichen Werten befüllen. Sie werden häufig in Datenbankanwendungen verwendet und generell Anwenddungen, welche mit relationalen Datenbanken arbeiten, um SQL-Injektionsangriffe zu verhindern und die Sicherheit der Anwendung zu verbessern. Generell kommen sie also bei Datenbankabfragen, Datenbankaktualisierungen und Datenbanktransaktionen zum Einsatz und werden in Schichten des Codes eingebaut,welche mit eben diesen Datenbankeninteraktionen verbunden sind. Dass können beispielsweise Serverseitige Skripte wie unsere Servlets sein, aber auch ORM-Frameworks.
Um die Funktionsweise zu veranschaulichen, sehen sie im Folgenden einen Beispielcode für ein Prepared Statement, welches für eine Datenbankabfrage zuständig ist, welche eine Tabelle: "user" mit den Spalten: "username" und "password" enthält. Das Prepared Statement wird mit der SQL-Anweisung erstellt, die Platzhalter für die Parameter enthält. In diesem Fall werden zwei Platzhalter verwendet, welche mit einem Fragezeichen gekennteichnet sind.
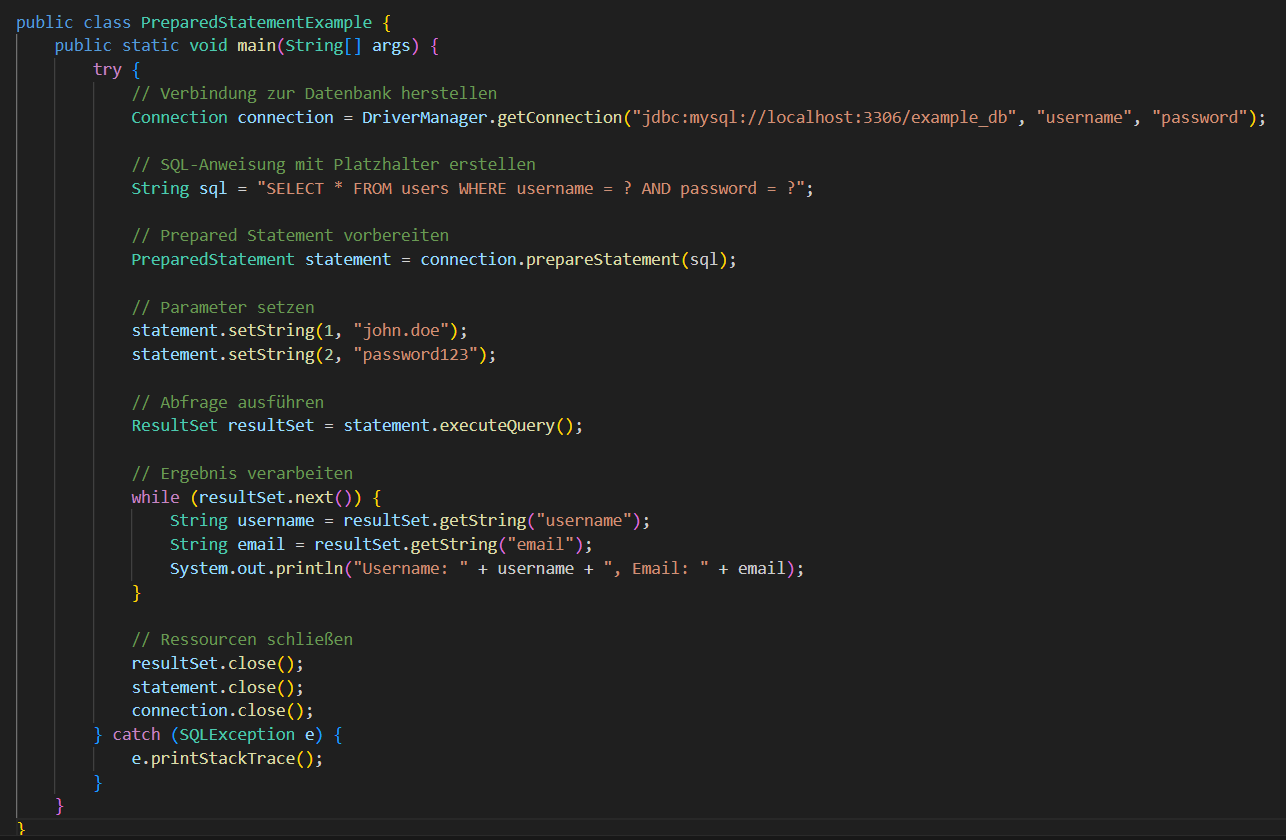
Die Parameter werden mit den tatsächlichen Werten über die entsprechenden Methoden (z. B. setString, setInt, usw.) gesetzt. In unserem Beispiel setzen wir den Benutzernamen und das Passwort. Dann wird das Prepared Statement mit executeQuery ausgeführt, um die Abfrage auszuführen. Das Ergebnis wird in einem ResultSet gespeichert und kann anschließend verarbeitet werden. Am Ende müssen alle Ressourcen (ResultSet, Statement, Connection) ordnungsgemäß geschlossen werden, um sicherzustellen, dass die Verbindung zur Datenbank dann freigegeben wird.
Verschlüsselung von HTTP zu HTTPS
Wie bereits erwähnt, habe ich mich für dieses Thema entschieden, da ich mich näher damit beschäftigen wollte, wie Webanwendungen geschütz werden und was genau der Unterschied zwischen HTTP und HTTPS ist. Natürlich war mir bekannt, dass HTTPS sicherer ist und man beim browsen im Internet darauf auchten sollte, ob websiten dies nutzen, um zu verhindern auf dupisoen Seiten zu landen und sich ungewolltem Zugriffen auf den eigenen Laptop auszusetzen. Was genau dahinter steckt, wusste ich allerdings nicht wirklich.
HTTPS erweitert das Netzwerkprotokol HTTP um den Faktor "Secure", was bedeutet, dass daten über HTTPS sicher im Web übertragen werden können. Dies wird durch Verschlüsselungsprotokolle gewährleistet, hier sind es SSL(Secure Sockets Layer) und sein Nachfolger TLS(Transport Layer Security). Allerdings kommen solche Netzwerkprotokolle nicht nur bei HTTPS zur Anwendung, es ist ledidlich das bekannteste Beispiel, sondern auch bei E-Mail Verschlüsselung, VPNs, API-Kommunikation usw. und es gibt natürlich auch alternative Verschlüsselungsprotokolle wie DTLS oder IPsec.
Kommen wir zurück zur Verschlüsselung von HTTPS durch SSL/TLS. Diese wurden entwickelt, um für eine Vertraulichkeit und Integrität der Datenübertragung zwischen einem Webserver und einem Client zu sorgen. Sie stellen also eine verschlüsselte Verbindung her, welche es potenziellen Angreifern erschwert, die übertragenen Daten abzufangen oder zu manipulieren. Die Grudnlegende Technologie basiert hier auf auf den node.js Krypto-Bibliotheken, welche eine Umfangreiche Sammlung von Kryptografiefunktionen, also Funktionen und Algorithmen, die für verschiedene Kryptografieanforderungen verwendet werden können, wie z. B. Verschlüsselung, Entschlüsselung, Erzeugung von Schlüsseln, Signierung, Verifikation usw. bereitstellen und innerhalb dessen eine eigene https-Bibliothekt haben. Dabei sichert asymmetrische Kryptographie den Austausch von Schlüsseln und symmetrische Kryptographie führt die eigentliche Datenverschlüsselung durch. Einfach gesagt, werden für den Austausch von Schlüsseln, unterschliedliche Schlüssel für Verschlüsselung und Entschlüsselung genutzt und für die Datenverschlüsselung, für beide Vorgänge der Selbe.
Um dieses Verschlüsselungsprotokoll nun in HTTPS zu Integrieren, fügt man dem Webserver, auf Ebene der Serverkonfiguration, sogenannte SSL/TLS-Zertifikate hinzu. Serverkonfiguartionen werden in sogrnannten Konfiguraationsdatein abgelegt, dies ist für unsere Betrachtung aber nur in der Hinsicht relevant, dass man verstehen sollte, dass es sich um eine Serverseitige technologie handelt. Ist das Zertifikat eingefügt, wird es von einer Zertifizierungsstelle (CA) ausgestellt und enthält Informationen über den Webserver sowie den öffentlichen Schlüssel des Servers. Wenn ein Client eine Verbindung zu einem HTTPS-fähigen Webserver herstellt, überprüft er das Zertifikat, um sicherzustellen, dass es von einer vertrauenswürdigen CA ausgestellt wurde und gültig ist. Anschließend wird eine verschlüsselte Verbindung hergestellt, um die Datenübertragung zu sichern.
Schauen wir uns mal ein einfaches Code-Beispiel in Java-Script an, welches die Verwendung von HTTPS in einer Node.js-Anwendung zeigt:
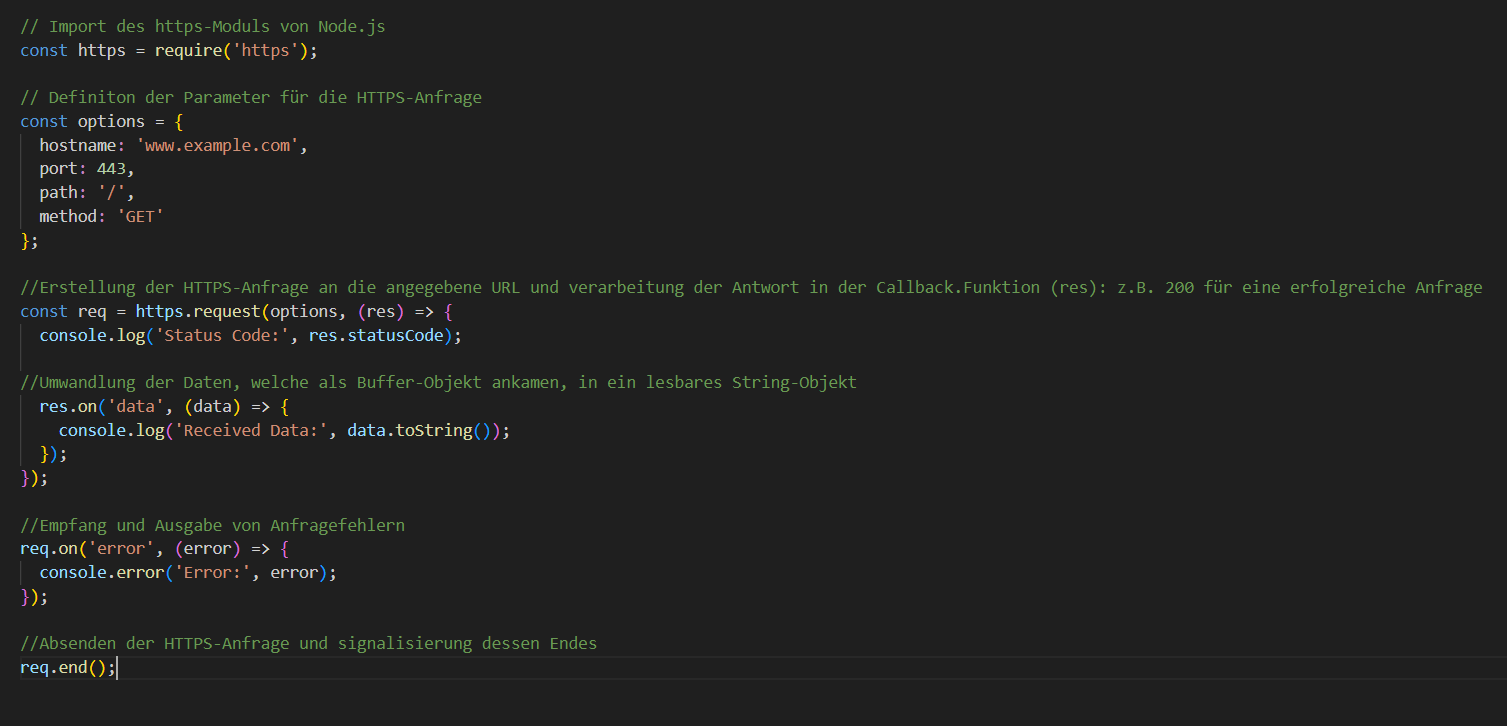
Abschließend würde ich gerne erwähnen, dass dieses Thema natürlich noch viel weiter ausgeführt werden könnte, ich denke jedoch, dies gibt bereits einen guten Überblick über die generellen Prinzipien der Sicherung von Webservern. Es ist und bleibt ein vielseitiges und spannendes Thema, welches sich kontinuierlich veröndert und weiterentwickelt und was uns auch in Zukunft immer weiter begleiten wird. Daher ist es wichtig, auch selbtt zu versuchen, so gut es geht, darauf zu achten die eigenen Daten zu schützen, denn wie man gesehen hat, gibt es viele ausgeklügelte Methoden wie ausenstehende versuchen an unsere Daten zu kommen und auch, wenn es viele Sicherheitsmechanismen gibt, gilt immer: "Vorsicht ist besser als Nachsicht".